Проект L.E.S. - технология разработки распределенных приложений для баз данных.
Вопрос с навигацией прояснился довольно быстро.
Все дело в том, что настольные СУБД типа dBASE, Paradox обеспечивают "прямой" доступ
к своим физическим таблицам,поэтому компоненты доступа Borland Delphi вроде TTable не
тратят много времени на открытие и навигацию по таким наборам данных.
В отличие от них СУБД MS SQL Server,Interbase и.т.д. основаны на реляционной модели Кодда,
т.е на теории множеств и вообще говоря не открывают прямой доступ к своим таблицам,а работают на запросах.
Все это очень хорошо,только о порядке записей приходится заботиться дополнительно.
Заранее прошу меня извинить за эти предварительные замечания, просто это
было достаточно давно, когда модной была еще 2-х звенная архитектура клиент-сервер.
Потом появились первые статьи о технологии MIDAS,3-х звенной архитектуре,толстых и тонких клиентах и так далее.
Напоследок, все же приведу достаточно давнее замечание менеджера компании Borland Сергея Орлика
(я считаю его очень грамотным специалистом и прекрасным популяризатором продуктов этой компании).
Речь здесь уже идет,как легко догадаться о 3-х звенной архитектуре и о ее стандартной реализации в виде COM-объекта,сервера-приложений или чего-то в этом роде..
Цитата :
"Вообще говоря понятие middleware принципиально отделено от баз данных. Не
забывайте, что хранимые процедуры даже официально (см. стандарт SQL DML)
называются "процедурными расширениями языка SQL". Я глубоко убежден (и это
мнение базируется не только на чтении аналитики, но и на реальных
проектах),
что хранимые процедуры должны использоваться только для тех задач, ради
которых существуют серверы баз данных, т.е. обеспечение непротиворечивого,
многопользовательского, гарантированного доступа к данным и хранения этих
данных с обеспечением их целостности (простите за такое
спонтанно-сформулированное определение серверов БД). Все остальные задачи
должны быть возложены на среднее звено - Middleware (являющееся шиной
обмена информацией и предоставляющее необходимые системные службы, такие как
безопасность, транзакционность, поиск объектов в сети, кластеризацию, баланс
загрузки и т.п. - см., например, OMG OMA) и серверы приложений,
предоставляющие контейнеры для размещения компонент бизнес-логики."
Вот здесь меня некоторые моменты смущают,а именно-это среднее звено стандартно
использует другие,отличные от СУБД средства хранения и обработки информации.
Как правило по запросу клиента на сервере создаются некоторые объекты,которые отвечают за обработку
его запросов.Обратите внимание на следующую фразу - поиск объектов в сети, кластеризацию, баланс
загрузки.
Т.е,говоря проще, по инициативе клиента выполняется создание промежуточного
объекта,преобразование данных в формат этого объекта и передача данных клиенту
через определенный интерфейс,а также обратная операция - получение данных
от клиента преобразование и запись изменений в базу.Когда клиентов много - таких объектов
тоже много,следовательно требуются большие ресурсы на сервере.Кроме того,а сколько данных
этот объект закачал к себе в память? Сколько "стоит" преобразование из формата базы в формат
этого объекта и обратно? Сколько данных них изменил клиент и как быстро остальные увидели эти
изменения? Здесь мне кажется стоит отметить один момент,если имеется огромное количество
унаследованного ПО,что для Запада актульно,то другого пути наверное и нет.Тогда наличие такого
объекта,который собирает данные из различных источников полностью оправдано.
Я считаю , что для реализации информационных проектов средней сложности можно использовать более простую и
как следствие более дешевую модель.Под стоимостью я понимаю как стоимость оборудования,так и стоимость сопровождения ПО.
Архитектура приложений 2,5.
Основная идея состоит в том,чтобы обеспечить быстрый скроллинг,изменение данных и
поиск при взаимодействии клиентской и серверной частей приложения , т.е отображения ,
только тех данных , которые необходимы в данный момент клиентской части приложения .
А как определить какие данные необходимы ?
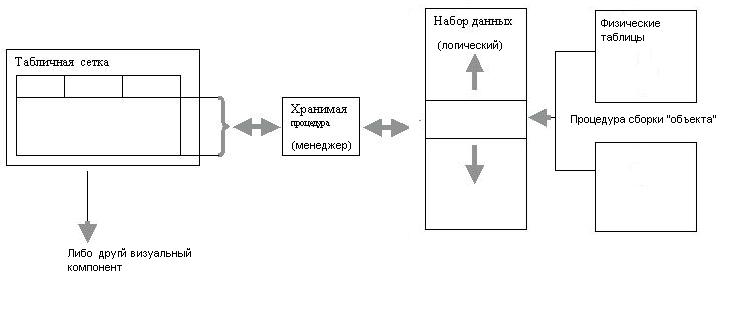
Ответ на этот вопрос "знает" интерфейсный элемент - табличная сетка и пр.
Здесь потребовалось создать потомков TDBGrid и TDataSet,чтобы обеспечить их эффективное взаимодействие
с базой данных.
Рис.1
Хранимая процедура обеспечивает сборку объекта,т.е позволяет отобразить не только
отдельные таблицы , но и результат выборки по оператору SELECT или вообще собирает данные нереляционным способом , отвечая при этом за
добавление удаление и изменение данных в исходных таблицах , которые участвуют в выборке.
При этом процедура "менеджер" может проверять права доступа пользователя , вести журналы,
вплоть до того , что может отдавать разным пользователям разные данные.
Кроме того она отвечает за перемещение по набору данных на сервере и
ответы на запросы пользовательского интерфейса.
Буквально она "умеет" следующее :
1.Выбрать пакет данных с начала набора.
2.Выбрать пакет данных с конца набора.
3.Выбрать пакет данных с определенного места.
4.Выбрать запись набора данных по критерию поиска.
5.Обеспечить сортировку данных.
6.Отфильтровать данные.
7.Удалить,добавить и изменить запись в наборе данных.
Все это она делает только пакетами,т.е допустим ищет запись и с этого места
в наборе данных формируется пакет записей,
например 10,который и передается интерфейсу.
Такая процедура генерируется по шаблону и может быть откорректирована средствами SQL.
В настоящее время это работает на MS SQL Server.Исследовалась возможность переноса на другие
СУБД, в частности на PostGreeSQL принципиальных трудностей не видно.